
Multi-Granular Transformer for Motion Prediction with LiDAR
Published in ICRA, 2024
Abstract
Motion prediction has been an essential component of autonomous driving systems since it handles highly uncertain and complex scenarios involving moving agents of different types. In this paper, we propose a Multi-Granular TRansformer (MGTR) framework, an encoder-decoder network that exploits context features in different granularities for different kinds of traffic agents. To further enhance MGTR’s capabilities, we leverage LiDAR point cloud data by incorporating LiDAR semantic features from an off-the-shelf LiDAR feature extractor. We evaluate MGTR on Waymo Open Dataset motion prediction benchmark and show that the proposed method achieved state-of-the-art performance, ranking 1st on its leaderboard.
Framework
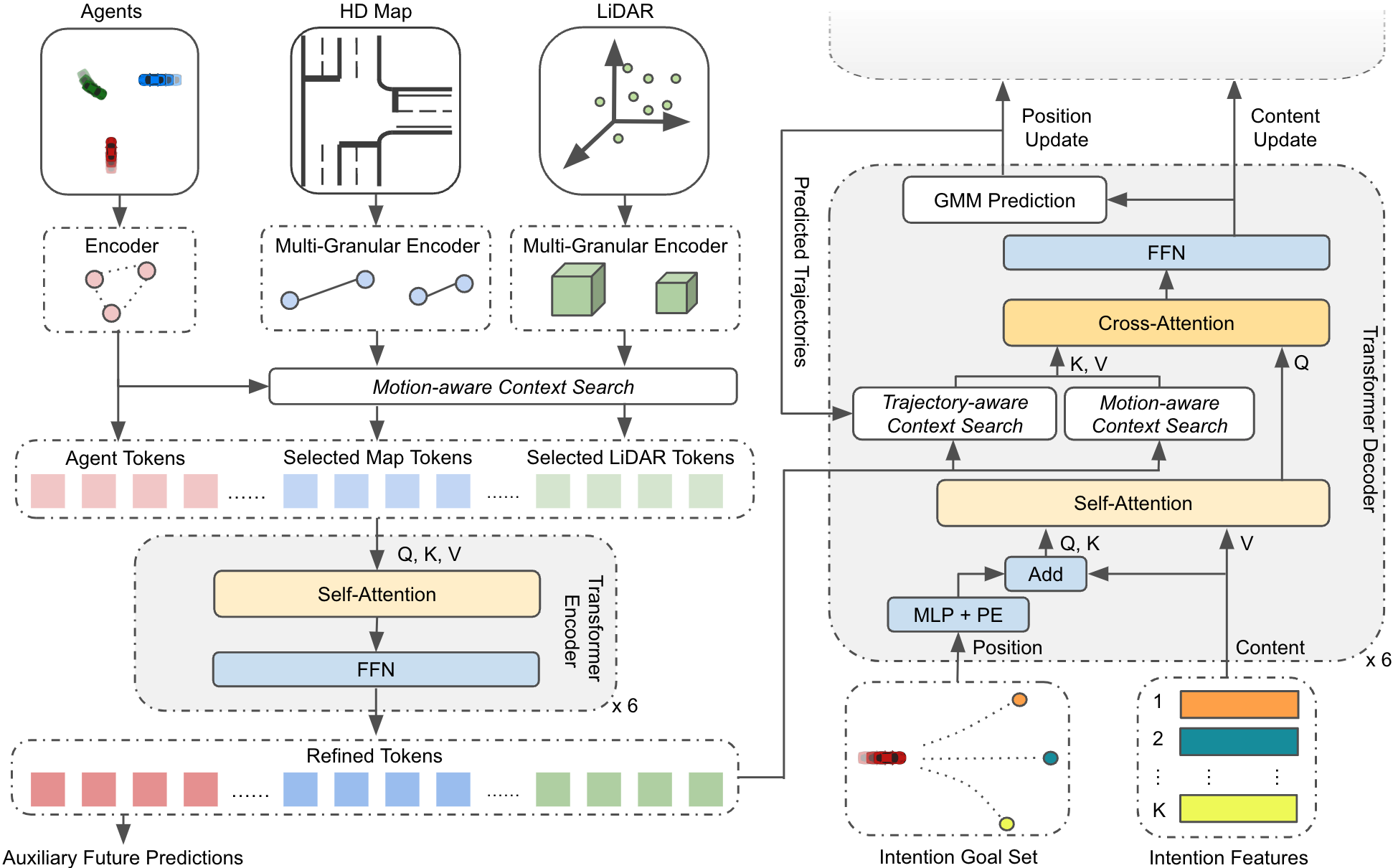
This figure illustrates the overview of our proposed approach. Agent trajectories and map elements are represented as polylines and encoded as agent and multi-granular map tokens. LiDAR data is processed by a pre-trained model into voxel features and further transformed into multi-granular LiDAR tokens. Motion-aware context search selects a set of map and LiDAR tokens, refined together with agent tokens through local self-attention in the Transformer encoder. Finally, a set of intention goals and their corresponding content features are sent to the decoder to aggregate context features. Multiple future trajectories of each agent will be predicted based on its intention goals, supporting the multimodal nature of agent behaviors.
Reference
Please cite this paper in your publications if it helps your research:
@article{gan2023multi,
title={Multi-Granular Transformer for Motion Prediction with LiDAR},
author={\textbf{Hao Xiao} and Gan, Yiqian and Zhao, Yizhe and Zhang, Ethan and Huang, Zhe and Ye, Xin and Ge, Lingting},
journal={2024 IEEE International Conference on Robotics and Automation (ICRA)},
year={2024}
}